Twproject indicizza ogni testo salvato nei suoi oggetti, come progetti, documenti, allegati, ToDo, risorse, commenti e così via.
Esso usa Lucene, un potente motore di ricerca open source.
Lucene è documentato qui:
http://lucene.apache.org/java/docs/index.html
Ci sono alcuni parametri da configurare: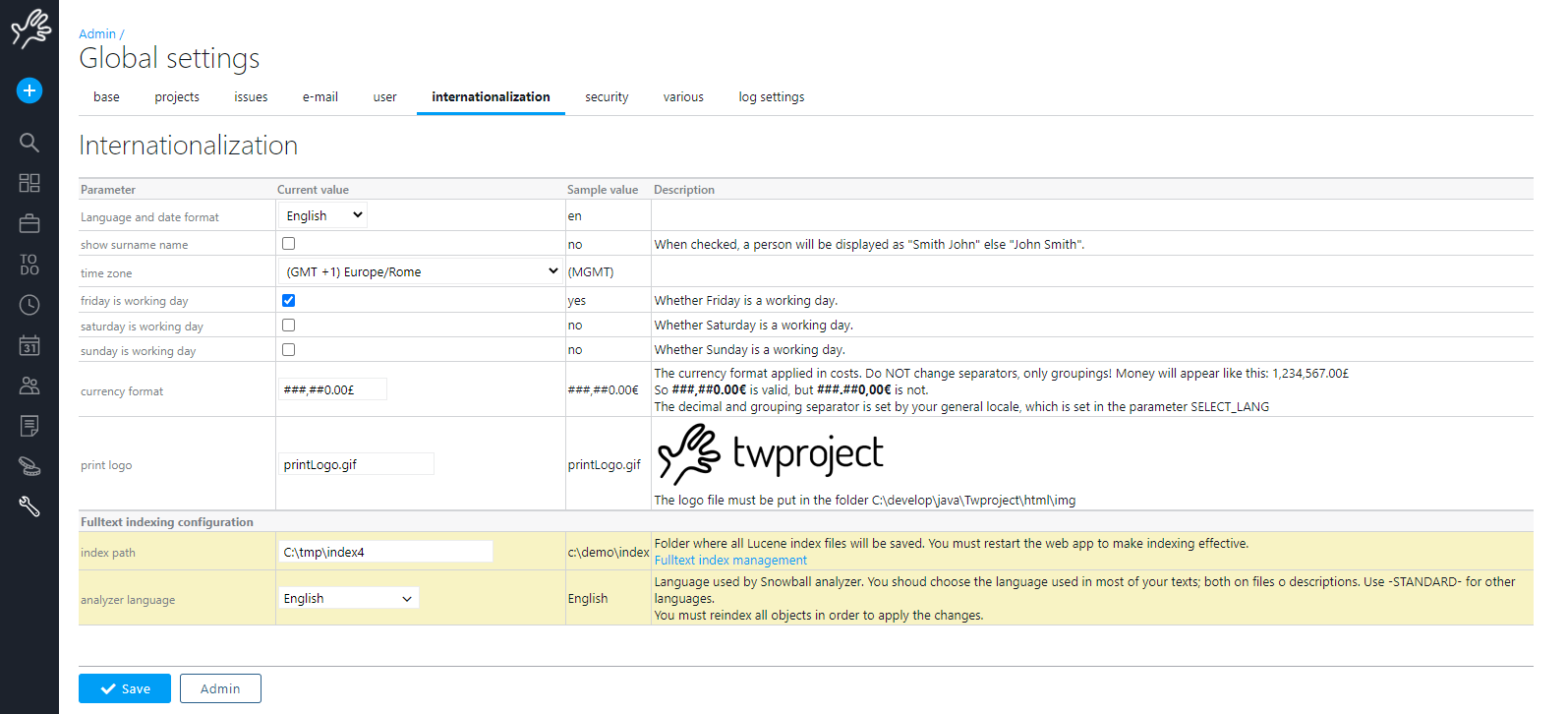
Prima di tutto la localizzazione del file di indice, poi la lingua dell’analyzer. Questo analyzer è usato per stemmare correttamente i tuoi dati. Lo stemming consente di cercare “work” e trovare anche “working”, ovviamente funziona bene se la lingua di ciò che stai scrivendo e lo stemmer coincidono.
In goni caso Twproject usa anche la corrispondenza esatta nelle ricerche.
Seguendo il link “index management”:
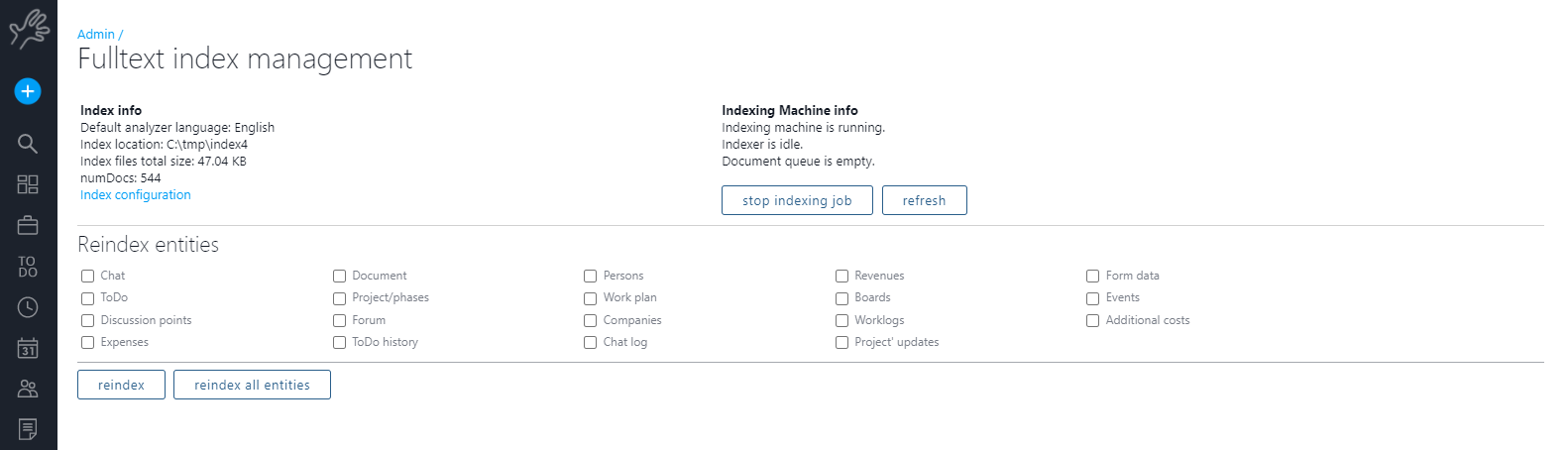
Qui puoi vedere lo stato della macchina di indicizzazione, interrompere il job o forzare una nuova indicizzazione.
User ranking
I punteggi sono usati da Twproject per valutare l’uso che gli utenti fanno del sistema. Il punteggio degli utenti è calcolato sulla base di valori, positivi e negativi, associati a diverse azioni. L’utente migliore ottiene il massimo dei punti, gli altri in proporzione.