Twproject indexes every text saved in its objects, like projects, documents, attachments, ToDos, resources, comments and so on.
It uses the powerful search engine open source Lucene.
Lucene is documented here:
http://lucene.apache.org/java/docs/index.html
There are some parameters you can configure:
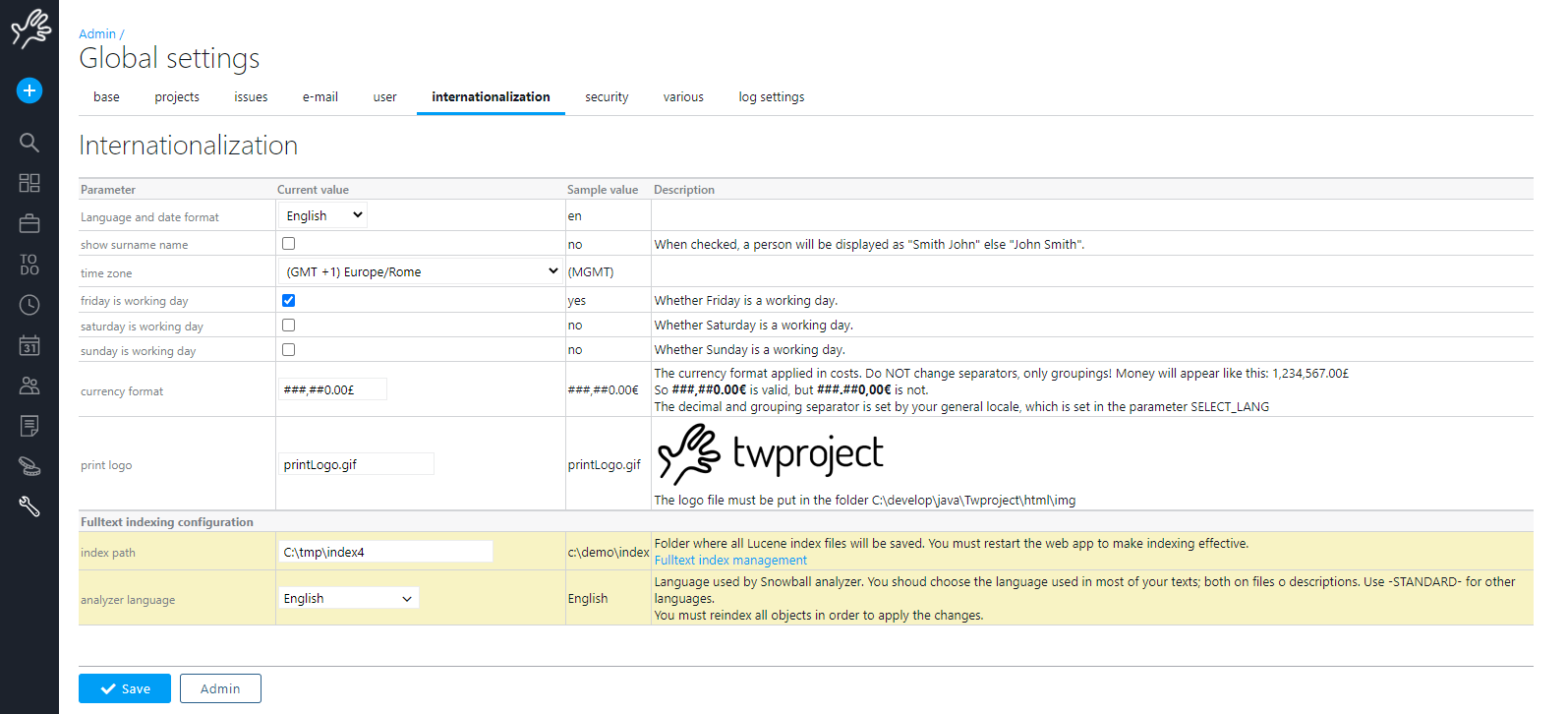
First of all the index files location, then the analyzer language. This analyzer is used to stem correctly your data. Stemming allows you to search “work” and find also “working”, of course it works correctly when the language you are writing data and the stemmer match.
In any case Twproject uses also exact matching in searches.
By following the “index management” link:
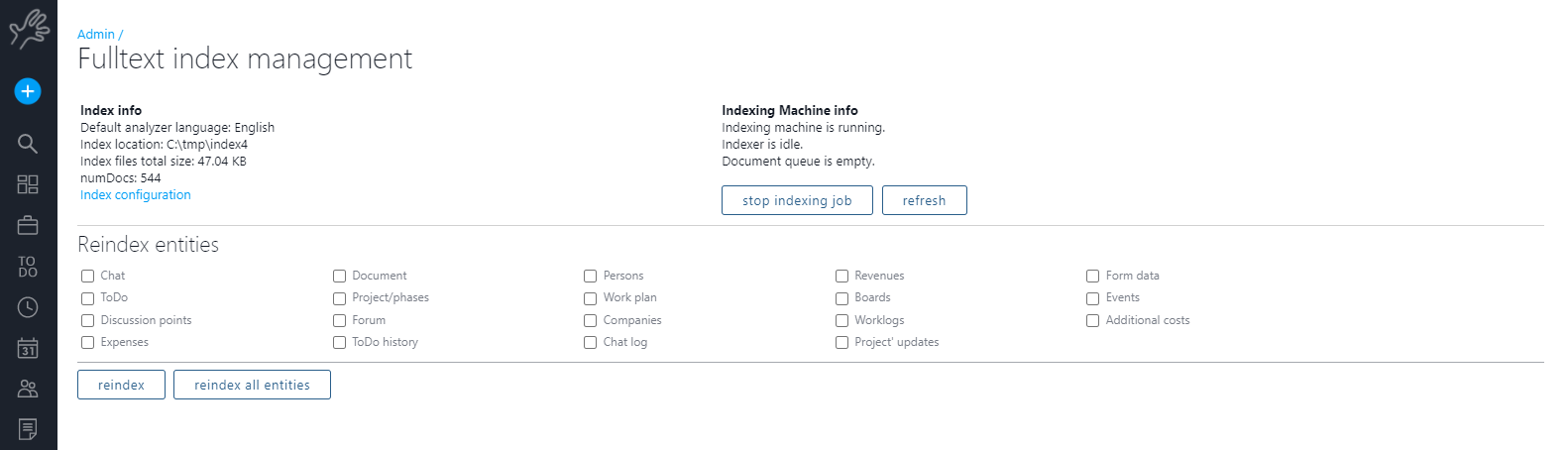
Here you can see the indexing machine status, stop the indexing job or force re-indexing.
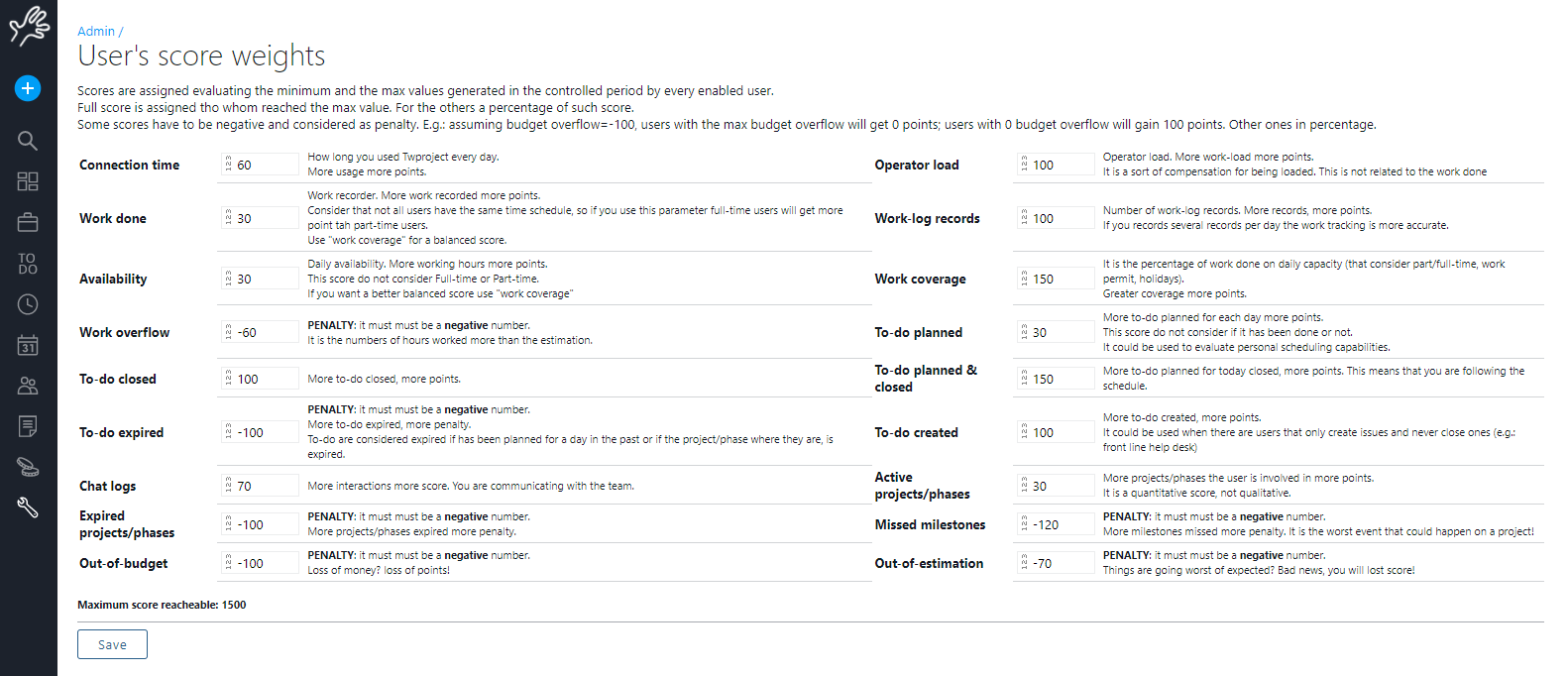
User Rank
Scores are assigned evaluating the minimum and the max values generated in the controlled period by every enabled user.
Full score is assigned tho whom reached the max value. For the others a percentage of such score.
Some scores have to be negative and considered as penalty. E.g.: assuming budget overflow=-100, users with the max budget overflow will get 0 points; users with 0 budget overflow will gain 100 points. Other ones in percentage.